ETL vs ELT
ETL and ELT are two data integration methodologies that are used to extract data from different sources, transform it into a consistent format, and load it into a data warehouse or data lake.
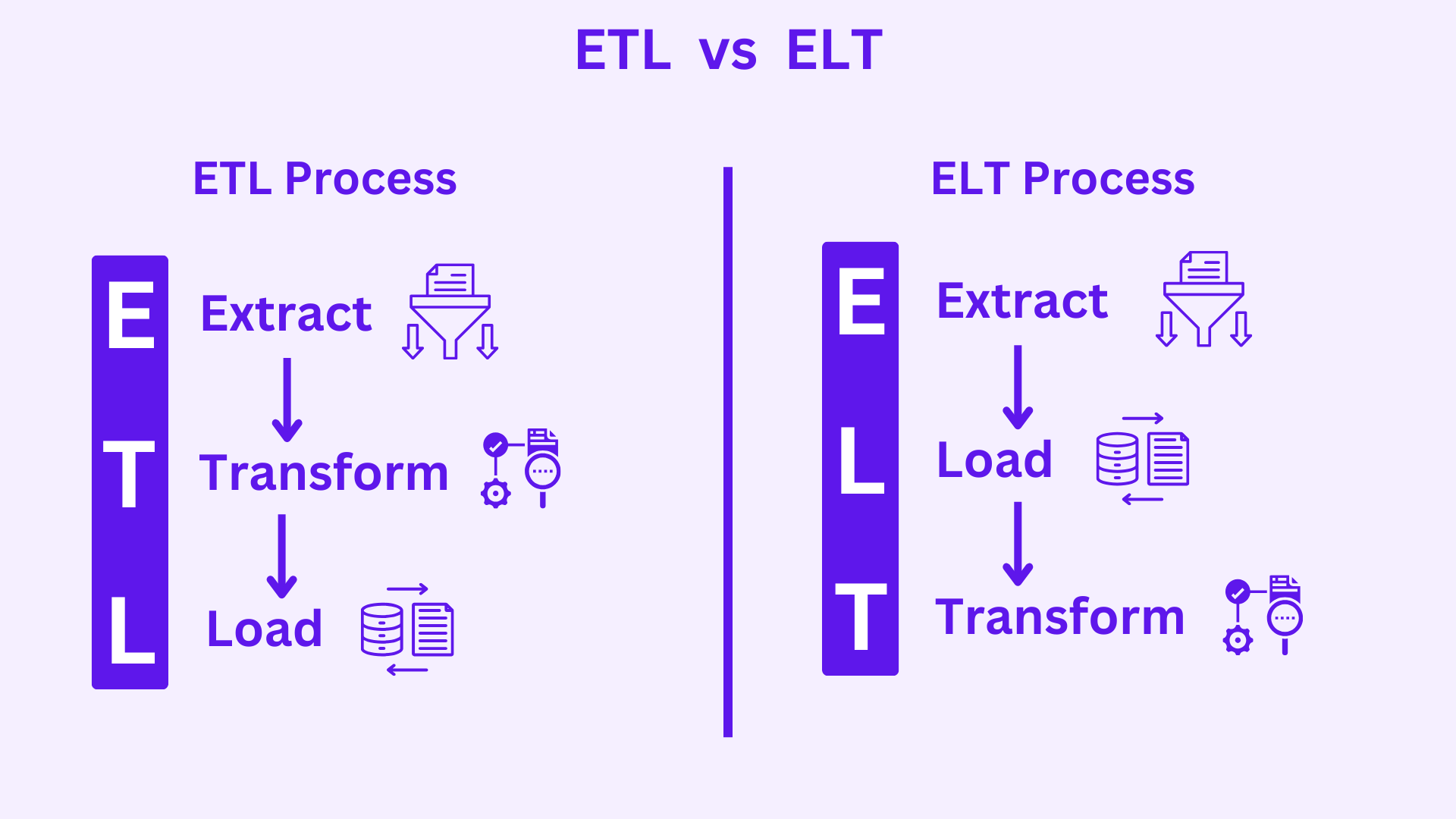
ETL stands for Extract, Transform, and Load.
The following steps are commonly included in the ETL process:
Extract: The data is extracted from the source systems.
Transform: The data is transformed into a consistent format. This may involve cleaning the data, removing duplicates, and converting data types.
Load: The data is loaded into the data warehouse or data lake.
ELT stands for Extract, Load, and Transform.
The ELT process typically involves the following steps:
Extract: The data is extracted from the source systems.
Load: the stored extracted data is loaded into the data warehouse or data lake.
Transform: The data is transformed in the data warehouse or data lake. This may involve cleaning the data, removing duplicates, and converting data types.
The order in which the data is changed is the main difference between ETL and ELT. ETL transforms data before it is loaded into a data warehouse or data lake. In ELT, data is initially put into the data warehouse or data lake and then converted.
Similarities between ETL and ELT
Both extract, transform, and load (ETL) and extract, load, and transform (ELT) are sequences of processes that prepare data for further analysis. They capture, process, and load data for analysis across three steps:
Extraction: Extraction is the first step of both ETL and ELT. This step is about collecting raw data from different sources.
Transformation: This step focuses on changing raw data from its original structure into a format that meets the requirements of the target system where you plan to store the data for analytics. Some transformation types are changing data types or formats, removing inconsistent or inaccurate data and removing data duplication.
Loading: In this step, the data is stored into the target database.
How do the ELT and ETL processes differ from each other?
ETL process has three steps:
- You extract raw data from various sources
- You use a secondary processing server to transform that data
- You load that data into a target database
These are the three steps of ELT process:
- You extract raw data from various sources
- You load it in its natural state into a data warehouse or data lake
- You transform it as needed while in the target system
With ELT, all data cleansing and transformation occurs within the data warehouse. You can use and transform the raw data as much as needed.
When to use ETL vs. ELT
ELT (extract, load, and transform) is the industry standard for modern analytics. However, in the following cases, you should consider extract, transform, and load (ETL).
Legacy Databases: It is sometimes more advantageous to use ETL to interface with legacy databases or third-party data sources that use predefined data formats. It simply needs to be transformed and loaded once into your system. You may use it more efficiently for all future analytics once it has been changed.
Experimentation: Experiments are carried out by data engineers in large organisations, such as identifying hidden data sources for analytics and testing novel concepts to solve business queries. ETL is important in data studies to better understand the database and its utility in a given context.
Complex analytics: ETL and ELT can be used jointly for complicated analyses that use numerous data formats from many sources. Data scientists can create ETL pipelines from some sources and use ELT for the rest. In some circumstances, this enhances analytics efficiency and increases the performance of applications.